18 · CLAUDE.md 使用指南:把项目规矩写进它的记忆
📚 系列导航:上一篇 17 图片与多模态 让你学会把截图、报错图直接喂给 Claude。这一篇换个方向——把项目的「规矩」一次性写进它的记忆,让它每次开工都自动遵守,不用你天天复读。
都说 CLAUDE.md 写得越详细越好,但说句实话,最没用的 CLAUDE.md,恰恰是那种写了三百行、Claude 一条都没听的。
设想一份接手项目里前任留下的 CLAUDE.md,洋洋洒洒:公司背景、产品愿景、团队介绍、技术选型的来龙去脉……翻到第二屏才看到一句有用的「用 pnpm 不用 npm」。结果呢?Claude 照样动不动给你 npm install。
问题不在它不听话,在那条规矩被埋在两百行废话里,注意力早被稀释没了。
CLAUDE.md(Claude 的项目记忆文件)这东西,写好了是神器,写砸了是负担——它每次会话都占你的上下文窗口,写得越臃肿,留给真正干活的空间越小。今天咱们就把这件事掰开:它分几层、该写什么、不该写什么、怎么引用别的文件、怎么维护精简。
看完这一篇,你会拿到:
- CLAUDE.md 三个层级(用户级 / 项目级 / 子目录级)各管什么、加载顺序怎么排
- 一张「该写 vs 不该写」的清单,避开 90% 新手往里塞废话的坑
- 用
@语法引用其他文件的正确姿势,以及它对上下文的真实代价 - 会话里临时补一条记忆的官方做法,加一套「好 vs 烂」对照表当模板
ℹ️ 本篇只聚焦 CLAUDE.md 这一个文件怎么写好、怎么维护。
/init一键生成的玩法在 12「项目初始化」 讲过了,更广的自动记忆(auto-memory)机制留给 25「记忆系统」 专门聊。
01 先搞懂:CLAUDE.md 到底是什么
先给结论:CLAUDE.md 是你写给 Claude 的一份「持久指令」,每次开会话它都先读一遍,当成项目背景装进脑子。
为什么需要它?因为每个 Claude Code 会话都从一张白纸开始——上次你苦口婆心交代的「用 pnpm、别碰 legacy 目录、测试这么跑」,这次它一概不记得。没有 CLAUDE.md,你就得每次重新解释一遍,烦不烦?
类比:给新员工的入职手册。 新人第一天来,你不会站他旁边全天候口述规矩。你给他一份手册:项目是干嘛的、代码怎么提交、哪几个雷区别踩。他自己看一遍就上手了。CLAUDE.md 就是 Claude 的入职手册——而且是每天上班前都会重读一遍的那种。
但这里有个关键认知,官方文档说得很直白:
CLAUDE.md 内容作为用户消息在系统提示之后传递,而不是系统提示本身的一部分。Claude 读取它并尝试遵循它,但没有严格遵守的保证。
翻译成人话:CLAUDE.md 是「强烈建议」,不是「铁律」。 它塑造 Claude 的行为,但不是硬性强制层。所以你写得越具体、越简洁,它遵守得越稳。指望靠它 100% 卡住某个危险操作?那是 Hook(钩子)的活儿,不是 CLAUDE.md 的活儿——这俩的分工后面篇章会讲。
什么时候该往里加内容?官方给了几个特别实在的信号:
- Claude 第二次犯同一个错 —— 说明这条得写进去固化下来
- 你这次会话又敲了一遍上次会话敲过的那句更正
- 代码审查时发现,它应该早就知道这个代码库的某个约定
- 新队友需要同样的背景才能快速上手
💡 一句话总结:CLAUDE.md 是 Claude 每次开工必读的入职手册,「强烈建议」级而非「铁律」级,写得越具体越管用。
02 三个层级:谁管全局,谁管单项目
CLAUDE.md 不止一份,它能放在好几个地方,作用范围从大到小。新手最容易在这儿犯迷糊,咱们一次理清。
按官方文档,常用的是这三层(外加一个本地变体):
| 层级 | 放哪儿 | 管多大范围 | 进不进 git |
|---|---|---|---|
| 用户级 | ~/.claude/CLAUDE.md | 你这台机器上所有项目 | 不进,纯个人偏好 |
| 项目级 | ./CLAUDE.md 或 ./.claude/CLAUDE.md | 当前这个项目 | ✅ 进,团队共享 |
| 子目录级 | 任意子目录/CLAUDE.md | Claude 读到那个目录的文件时才加载 | ✅ 进,适合多模块仓库 |
| 本地级(变体) | ./CLAUDE.local.md | 当前项目,只你自己 | ❌ 加进 .gitignore |
还有一层「托管策略层」,由 IT 管理员部署到系统目录(macOS 为
/Library/Application Support/ClaudeCode/CLAUDE.md),在用户级之前加载、不可被个人排除。个人用户通常碰不到,本篇略去;企业场景可查官方文档。
怎么分工?记一句话:个人习惯放用户级,团队规矩放项目级。
- 用户级(
~/.claude/CLAUDE.md):放跨项目通用的个人偏好。比如「回复用中文」「改代码前先说思路别直接上手」「提交信息用英文」。这些跟具体项目无关,是「你这个人」的习惯,所以对所有项目生效、不进任何项目的 git。 - 项目级(
./CLAUDE.md):放这个项目专属、且全队都该守的规矩。技术栈、构建命令、目录约定、禁改清单。它跟着代码进版本控制,新同事 clone 下来就自带这套规范。 - 子目录级:大仓库才用得上。比如前端目录放一份前端专属的,后端目录放一份后端专属的。它平时不加载,只有当 Claude 真去读那个目录里的文件时,才顺手把那份 CLAUDE.md 带进来——省上下文。
类比还是入职手册: 用户级 = 你个人的工作习惯本(换公司也带着);项目级 = 这家公司发的员工手册(离职就还回去);子目录级 = 某个部门内部的额外细则(只有调到那个部门才发给你)。
举个常见的用户级配置:在 ~/.claude/CLAUDE.md 里放一句「遇到多种实现方案时,列出选项让我选,而不是默默替我决定」。这条对你每个项目都成立,所以放用户级最省事——一次配上之后,再不用在某个新项目里重新交代这句话。
💡 一句话总结:个人习惯写用户级(
~/.claude/CLAUDE.md),团队规矩写项目级(./CLAUDE.md进 git),大仓库再用子目录级按模块拆。
03 加载顺序:项目级为什么「后说话更管用」
上一节列了三层,那它们同时存在时,谁说了算?这是另一个高频误区,得讲准。
官方的规则:从最广的范围到最具体的范围依次加载,越靠近你启动目录的指令,越晚被读到。
具体怎么排?Claude Code 从你当前所在的目录一路往上走,沿途每一层有 CLAUDE.md 就收进来,最后拼成一整块上下文。顺序大致是:
text
用户级 ~/.claude/CLAUDE.md
↓(先读)
(目录树里更靠上的)父目录 CLAUDE.md
↓
项目根 ./CLAUDE.md
↓(后读,离你最近)
子目录 CLAUDE.md(只有 Claude 读那个目录的文件时才加进来)注意两个要点,都来自官方文档:
第一,所有找到的文件是「拼接」不是「覆盖」。 它们全都进上下文,不是后面的把前面的顶掉。所以用户级和项目级同时生效,不存在「设了项目级,用户级就失效」。
第二,更靠近工作目录的指令「最后被读到」。 当两条规矩打架时——比如用户级说「字符串用单引号」、项目级说「用双引号」——离得近的项目级因为后说话,通常更占优。说白了,项目规矩能盖过你的个人习惯,这正是团队协作想要的效果。
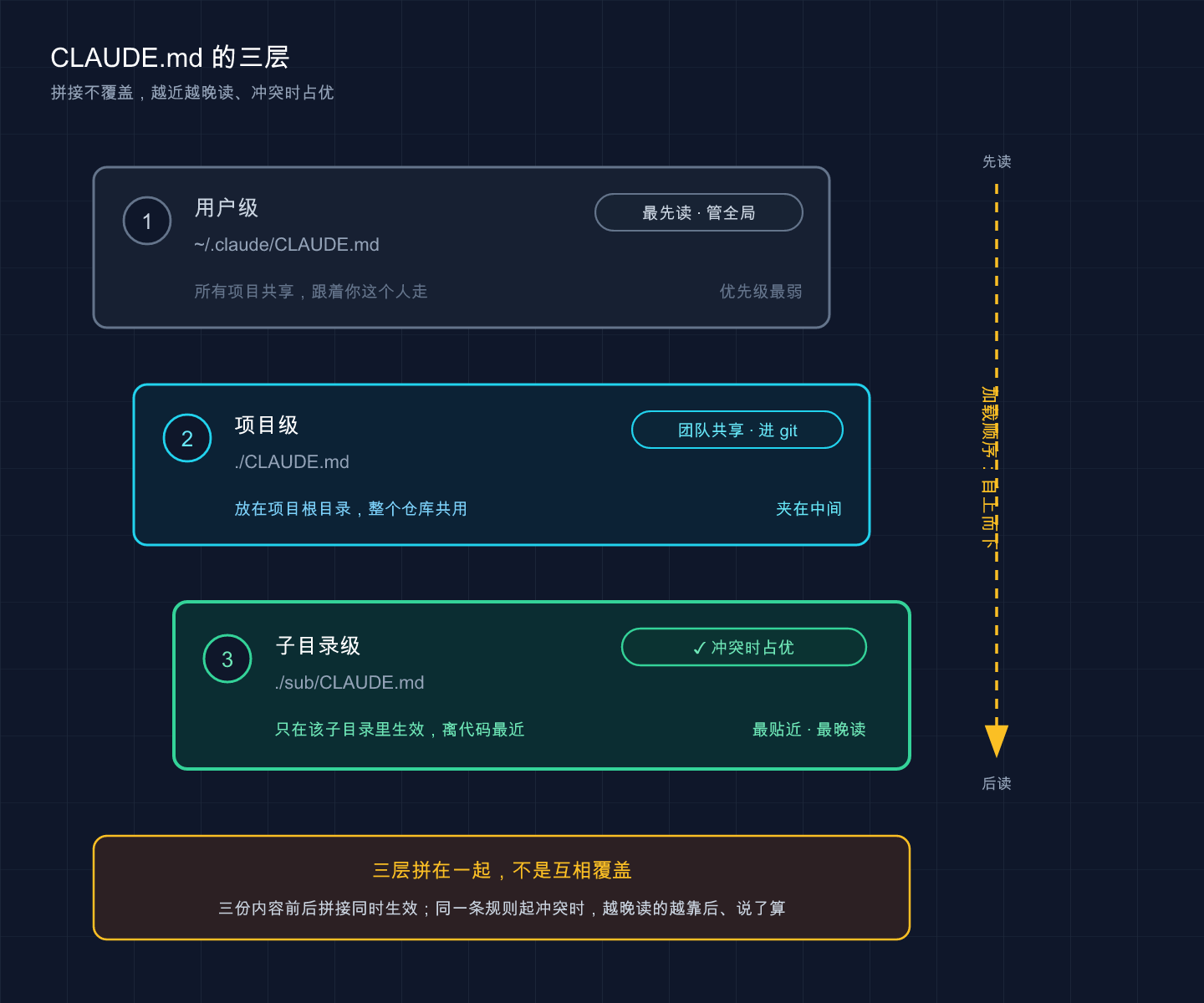
这张图把三层从上到下叠在一起:用户级(管所有项目、最先读)、项目级(当前项目、进 git)、子目录级(离代码最近、冲突时占优);右侧箭头标出「从上往下」的加载顺序,底部那条铁律点明——三层是拼接、不是覆盖,越靠近代码的越晚读、说了算。
这里还得纠一个常见的错误说法。网上不少教程把优先级写成「项目本地 → 项目根 → 子目录 → 全局」,这跟官方描述的加载方向是反的。很容易被这种说法带偏,但翻官方文档就清楚了:官方明确说是「从最广泛的范围到最具体的范围」加载,项目指令出现在用户指令之后。以官方为准,别记反了。
还有个贴心细节:项目根的 CLAUDE.md 在 /compact(压缩对话)之后会自动从磁盘重新读回来,不会丢。但子目录里那些嵌套的 CLAUDE.md 不会自动重注入,得等 Claude 下次读那个目录的文件才回来。所以重要规矩尽量放项目根,别埋太深。
💡 一句话总结:多层 CLAUDE.md 是拼接不是覆盖,越靠近工作目录的越晚读、冲突时越占优,所以项目规矩能盖过个人习惯——别把官方的加载方向记反了。
04 该写什么 vs 不该写什么
这一节是全篇的命门。CLAUDE.md 写不好,九成是栽在「该写的没写清,不该写的塞一堆」。
先说该写的——官方一句话点透:写「Claude 应该在每个会话中都保持的事实」。 翻成清单就是这五类:
| 类别 | 具体写什么 | 例子 |
|---|---|---|
| 项目概述 | 一句话说清这是个啥项目 | 「基于 FastAPI 的订单管理后端」 |
| 技术栈 | 语言、框架、数据库、关键工具 | 「Python 3.11 / PostgreSQL / pytest」 |
| 常用命令 | 测试、构建、检查怎么跑 | uv run pytest、uv run ruff check . |
| 代码约定 | 风格、命名、必须遵守的写法 | 「函数必须有类型注解」「字符串用双引号」 |
| 明确的「不要做」 | 雷区、禁改文件、必须先问的操作 | 「禁改 migrations/ 已有文件」 |
其中常用命令是被参考最频繁的——Claude 跑测试、构建前会先来这儿翻命令,省得它瞎猜或者用错。禁止清单则是防它「聪明但闯祸」的护栏:哪些目录是遗留代码只读不改、哪个文件改之前必须先告诉你、哪些密钥文件禁止输出内容。
再说不该写的,这才是新手翻车重灾区:
- ❌ 长篇大论的背景:公司介绍、产品愿景、技术选型的历史渊源——Claude 写代码用不上,纯占上下文。
- ❌ 过时信息:换了包管理器却没更新 CLAUDE.md,里面还写着 npm,结果误导它。
- ❌ 看代码就知道的东西:别去复述目录结构里每个文件干啥、别把 ESLint 配置已经定义的代码风格再抄一遍。Claude 自己会读代码,复述等于白占空间。
官方对这事的态度很明确,专门给了大小红线:
每个 CLAUDE.md 文件目标在 200 行以下。较长的文件消耗更多上下文并降低遵守度。
为什么 200 行这么要紧?因为 CLAUDE.md 跟你的对话抢同一个上下文窗口。你塞进去三百行废话,等于一开局就占掉一大块工作台,留给真正任务的空间反而缩水——而且重要规矩淹在废话里,注意力被稀释,遵守度不升反降。这就是开头那个「三百行没人听」的病根。
有个好用的土办法:写每一条之前先自问一句「这条 Claude 看代码能不能自己推出来?能,就删」。 就靠这一刀,能把一份接手项目的 CLAUDE.md 从三百多行砍到八十行,留下的全是它推不出来的硬约束——砍完之后,它用错包管理器的次数肉眼可见地降下去。
💡 一句话总结:写「每个会话都该记住的事实」(概述 / 技术栈 / 命令 / 约定 / 禁区),删一切 Claude 看代码能自己推出来的东西,全文压在 200 行以内。
05 引用其他文件:@ 语法与它的代价
有时候你项目里已经有现成的规范文档了——一份 API 设计指南、一份数据库约定。没必要把内容复制进 CLAUDE.md,用 @ 语法引用就行。
写法很简单,在 CLAUDE.md 里任意位置写 @ 加路径:
text
有关项目概述,请参阅 @README,可用命令见 @package.json。
# 其他指令
- git 工作流 @docs/git-instructions.mdClaude 读 CLAUDE.md 时,会把这些引用的文件内容展开、一起加载进上下文。几个官方明确的细节,记牢了别踩坑:
- 相对路径相对于「包含引用的那个文件」解析,不是相对于你的工作目录。这点容易搞错。
- 绝对路径也行;引用的文件还能再引用别的文件,最多递归四跳。
- 第一次遇到项目外的引用,Claude Code 会弹个批准框列出这些文件让你确认;你拒了,这个引用就一直禁用,框也不再弹。
但这里有个最关键的认知,官方反复强调,也是最容易踩的坑:
导入的文件在启动时展开并加载到上下文中。分割到
@path导入有助于组织,但不会减少上下文,因为导入的文件在启动时加载。
说白了:@ 引用是「整理」,不是「省钱」。 很多人以为把内容拆到外部文件、CLAUDE.md 本体变短了,上下文就省了——错。 被引用的文件照样在开局全量加载进窗口,该占的上下文一点没少。设想把一份五百行的规范拆出去用 @ 引,以为瘦身了,结果 /context(查看上下文占用)一看,该吃的 token 一个没落下。
所以原则是:@ 引用用来让结构更清爽、便于人类维护,但要省上下文,得靠「精简内容」或「路径范围规则」,不是靠拆文件。 引用的单个文件也别太大,太大照样拖累。
顺带提一个相关的:如果你有些纯个人、不想进 git 的项目偏好(比如你本地的沙箱 URL、爱用的测试数据),别写进 ./CLAUDE.md,写进 ./CLAUDE.local.md,再把它加进 .gitignore。它跟 CLAUDE.md 一起加载、处理方式完全一样,只是不会被提交、不影响队友。
💡 一句话总结:
@路径把外部文档引进来是为了「结构清爽」,但被引用的内容照样全量进上下文、不省 token;想省得真删内容;私人偏好放CLAUDE.local.md并 gitignore。
06 维护:会话里随手补、定期精简
CLAUDE.md 不是写完一次就供起来的,它得跟着项目长。这节讲两个维护动作:怎么随手补一条、怎么定期瘦身。
会话里临时想补一条怎么办
经常是这样:聊着聊着你纠正了 Claude 一句,心想「这条以后每次都该守,得记下来」。最省事的官方做法——直接在对话里跟它说:
text
把「数据库操作必须走 Service 层,别在路由里直接写 SQL」这条加进 CLAUDE.mdClaude 会帮你把这条写进 CLAUDE.md 文件。你也可以随时敲 /memory 命令,它会列出当前会话加载的所有 CLAUDE.md、CLAUDE.local.md 和规则文件,点一下就在编辑器里打开,手动改也行。想让 Claude 自己决定怎么措辞就用第一种;想精确控制措辞就用 /memory 自己编辑。
ℹ️ 一个版本差异提醒:早期 Claude Code 里,在输入框用
#开头打一句话能快速追加记忆。新版本里这套交互已经变了——以官方现在的做法为准:要么直接让 Claude「加进 CLAUDE.md」,要么用/memory自己编辑。你敲一句「记住 xxx」,Claude 默认多半存进它自己的自动记忆(auto-memory,那是 25「记忆系统」 的话题);想明确进 CLAUDE.md,就把「加进 CLAUDE.md」这句话说全。
定期精简,删掉过时和打架的
官方点名的一个隐患:两条规矩互相矛盾时,Claude 可能随便挑一条听。 所以得定期回头审视,把过时的、冲突的清掉。该触发精简的时机:
- 换了包管理器 / 构建工具(旧命令必须删,留着就是误导)
- 加了或去了重要依赖
- 定了新的编程约定(顺手检查跟老规矩冲不冲突)
- 发现 CLAUDE.md 又悄悄涨过 200 行
判断一条规矩好不好,就看它像不像「规则」而非「散文」。官方给的对照特别实用,我整理成表:
| ❌ 模糊散文(没用) | ✅ 具体规则(管用) |
|---|---|
| 代码应该比较整洁 | 函数不超过 50 行,超了必须拆 |
| 尽量写测试 | 每个新增函数都必须有对应单元测试 |
| 注意安全 | 用户输入必须先过 sanitize() 再进数据库查询 |
| legacy 目录不太重要 | 禁止修改 legacy/ 目录下任何文件 |
| 用 pnpm 比较好 | 依赖管理只用 pnpm,禁用 npm 和 yarn |
左边那种话等于没说——「整洁」「尽量」「注意」全是主观词,Claude 没法验证、自然没法稳定执行。右边每一条都具体到能验证:50 行、必须有测试、必须过某函数。官方的原话就是「编写具体到足以验证的指令」。
写 CLAUDE.md 不妨养成一个硬习惯:每条规矩写完,自己当裁判判一下「这条能不能用一眼看出有没有违反」。判不了的,就是写虚了,回去改具体。
💡 一句话总结:随手补一条就让 Claude「加进 CLAUDE.md」或用
/memory编辑;定期删过时和打架的规矩;好规矩长得像「能一眼验证的规则」,不是「整洁、尽量」这种散文。
07 动手:给玩具项目配一份合格的 CLAUDE.md
光说不练没用。下面用一个最小项目,走一遍「建文件 → 写规矩 → 验证加载」的完整流程。跟着敲,五分钟搞定。
第一步:建个玩具项目并初始化 git(Mac / Linux)
bash
mkdir claude-md-demo
cd claude-md-demo
git init
echo 'def add(a, b):
return a + b' > main.py预期:claude-md-demo 目录里有一个 main.py 和一个 .git 目录。git 初始化是为了让这份 CLAUDE.md 能进版本控制(团队共享的前提)。
第二步:手写一份精简的项目级 CLAUDE.md
用你顺手的编辑器,在项目根目录新建 CLAUDE.md,贴入下面这份(注意它一共没几行——这就是好 CLAUDE.md 该有的样子):
markdown
# add-demo — 一个演示用的最小 Python 项目
只有一个 `add` 函数,用来演示 CLAUDE.md 怎么写。
## 常用命令
- `python -m pytest` —— 运行测试
## 编程约定
- 所有函数必须有类型注解
- 字符串一律用双引号
## 注意事项
- 不要修改 `main.py` 里 `add` 的函数签名,只能在内部加逻辑预期:项目根目录下出现 CLAUDE.md,内容就是上面这几节。全文不到 15 行——记住这个篇幅感,真实项目也别失控膨胀。
第三步:启动 Claude,验证它真读到了
在项目目录里启动:
bash
claude启动后,敲这个命令确认加载情况:
text
/memory预期:列表里能看到你刚写的 ./CLAUDE.md。只要它在列表里,就说明 Claude 这次会话确实把它装进上下文了。 这一步是官方推荐的排查手段——要是某条规矩没被遵守,第一件事就是 /memory 看文件到底加载了没。
第四步:让它干一件「踩约定」的活,看它守不守规矩
退出 /memory 回到输入框,敲:
text
给 add 函数加上类型注解预期:Claude 给出的 diff 里,类型注解用的是项目约定的写法,而且不会去动函数签名以外它被禁止改的部分。如果它老老实实按你 CLAUDE.md 里「函数必须有类型注解」来改——恭喜,这份入职手册生效了。
⚠️ 万一发现它没按 CLAUDE.md 来:先
/memory确认文件加载了;再检查那条规矩是不是写得太模糊(「整洁」这种);最后看有没有两条规矩在打架。这三步是官方给的标准排查顺序,照着走基本能定位。
💡 一句话总结:走一遍「建文件 → 写不到 15 行的精简规矩 →
/memory确认加载 → 让它干活验证守不守规矩」,没生效就按/memory→ 查模糊 → 查冲突这套官方顺序排查。
08 小结
这一篇你把 CLAUDE.md 这个「Claude 的项目记忆」从头到尾摸清了:
| 维度 | 关键结论 |
|---|---|
| 是什么 | 每次会话必读的入职手册,「强烈建议」级,非铁律 |
| 分几层 | 用户级(个人)/ 项目级(团队进 git)/ 子目录级(按需) |
| 加载顺序 | 拼接不覆盖,越近越晚读、冲突时占优 |
| 写什么 | 概述 / 技术栈 / 命令 / 约定 / 禁区,删一切代码能自证的 |
@ 引用 | 整理结构用,不省上下文(照样全量加载) |
| 维护 | 让 Claude「加进 CLAUDE.md」或 /memory 编辑;定期删过时冲突;像规则别像散文 |
你现在应该能: 判断一条信息该不该进 CLAUDE.md、放哪一层;写出具体到能验证的规矩而不是空话;用 @ 引用外部文档同时清楚它的上下文代价;项目跑久了知道怎么随手补、定期瘦身。一句话——你能写出一份 Claude 真愿意听、而不是写了三百行没人理的 CLAUDE.md 了。
下一篇 19「上下文管理」——这篇里反复提到「CLAUDE.md 会占上下文窗口」「@ 引用照样全量加载」,那这个上下文窗口到底是什么、满了会怎样、/context 和 /compact 又怎么用?下一篇就专门把这块工作台讲透。留个小思考:你觉得一份 CLAUDE.md 占掉的 token,和你一整段对话比,哪个更耗?